
 youngwoon
7feb637ba9
add coeff for gan loss
youngwoon
7feb637ba9
add coeff for gan loss
|
6 年之前 | |
|---|---|---|
| assets | 7 年之前 | |
| .gitignore | 7 年之前 | |
| LICENSE | 8 年之前 | |
| README.md | 7 年之前 | |
| bicycle-gan.py | 6 年之前 | |
| data_loader.py | 7 年之前 | |
| discriminator.py | 7 年之前 | |
| download_pix2pix_dataset.sh | 7 年之前 | |
| encoder.py | 7 年之前 | |
| generator.py | 7 年之前 | |
| model.py | 6 年之前 | |
| ops.py | 7 年之前 | |
| utils.py | 7 年之前 |
README.md
BicycleGAN implementation in Tensorflow
As part of the implementation series of Joseph Lim's group at USC, our motivation is to accelerate (or sometimes delay) research in the AI community by promoting open-source projects. To this end, we implement state-of-the-art research papers, and publicly share them with concise reports. Please visit our group github site for other projects.
This project is implemented by Youngwoon Lee and the codes have been reviewed by Yuan-Hong Liao before being published.
Description
This repo is a Tensorflow implementation of BicycleGAN on Pix2Pix datasets: Toward Multimodal Image-to-Image Translation.
This paper presents a framework addressing the image-to-image translation task, where we are interested in converting an image from one domain (e.g., sketch) to another domain (e.g., image). While the previous method (pix2pix) cannot generate diverse outputs, this paper proposes a method that one image (e.g., a sketch of shoes) can be transformed into a set of images (e.g., shoes with different colors/textures).
The proposed method encourages diverse results by generating output images with noise and then reconstructing noise from the output images. The framework consists of two cycles, B -> z' -> B' and noise z -> output B' -> noise z'.

The first step is the conditional Variational Auto Encoder GAN (cVAE-GAN) whose architecture is similar to pix2pix network with noise. In cVAE-GAN, a generator G takes an input image A (sketch) and a noise z and outputs its counterpart in domain B (image) with variations. However, it was reported that the generator G ends up with ignoring the added noise.
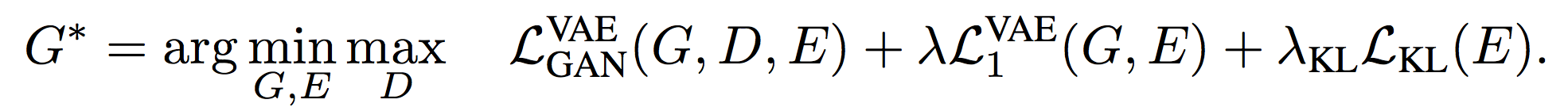
The second part, the conditional Latent Regressor GAN (cLR-GAN), enforces the generator to follow the noise z. An encoder E maps visual features (color and texture) of a generated image B' to the latent vector z' which is close to the original noise z. To minimize |z-z'|, images computed with different noises should be different. Therefore, the cLR-GAN can alleviate the issue of mode collapse. Moreover, a KL-divergence loss KL(p(z);N(0;I)) encourages the latent vectors to follow gaussian distribution, so a gaussian noise can be used as a latent vector in testing time.
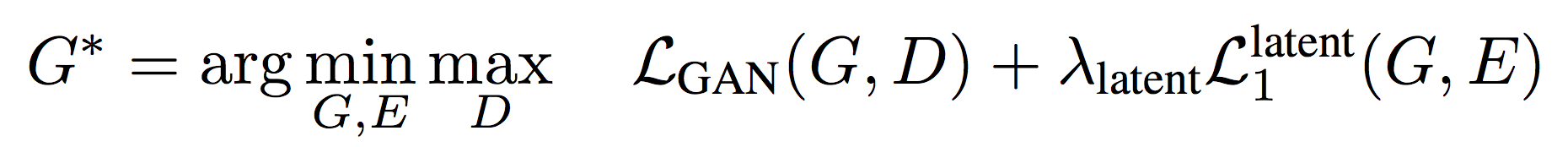
Finally, the total loss term for Bi-Cycle-GAN is:
<img src="assets/Bi-Cycle-GAN-loss.png" width=500>
Dependencies
Usage
- Execute the following command to download the specified dataset as well as train a model:
$ python bicycle-gan.py --task edges2shoes --image_size 256
- To reconstruct 256x256 images, set
--image_sizeto 256; otherwise it will resize to and generate images in 128x128. Once training is ended, testing images will be converted to the target domain and the results will be saved to./results/edges2shoes_2017-07-07_07-07-07/. Available datasets: edges2shoes, edges2handbags, maps, cityscapes, facades
Check the training status on Tensorboard:
$ tensorboard --logdir=./logs
Results
edges2shoes
| Linearly sampled noise | Randomly sampled noise |
|---|---|
 |
 |
 |
 |

day2night
In-progress